Neural Integration of Iterative Reasoning: A Technical Deep Dive into Context-Aware Code Generation
Soran Ghaderi
University of Essex, September 2024
Abstract
Despite advances in large language models (LLMs) for code generation, they still struggle in effectively utilizing contextual information throughout the generation process. To tackle this challenge, we introduce the Neural Integration of Iterative Reasoning (NIR) framework, which offers a new method for incorporating Context Representation Vectors (CRVs) at multiple levels within LLMs. NIR boosts the ability of these models to generate code without needing fine-tuning, allowing it to be used across various LLM architectures. We assess NIR by testing it with LLaMA 3.1 on the MBPP dataset, focusing on early, mid, and deep integration stages. Our experiments show that the depth of CRV integration has a notable impact on several facets of code generation, including response rates, syntactic correctness, and overall code structure. Deeper integration generally improves syntactic accuracy and code conciseness, while mid-layer integration shows optimal performance in semantic tasks. We report detailed evaluation metrics that assess code quality, complexity, and structure. Our findings indicate possible trade-offs among various code quality measures and emphasize the potential of adaptive integration strategies. While NIR demonstrates promising results, we also identify limitations such as dataset specificity and output inconsistencies. This study contributes to understanding contextual information processing in LLMs and might be useful for future developments in codeLLMs. We conclude by outlining future research directions, including multi-layer integration and dynamic adaptation strategies.
1. Introduction
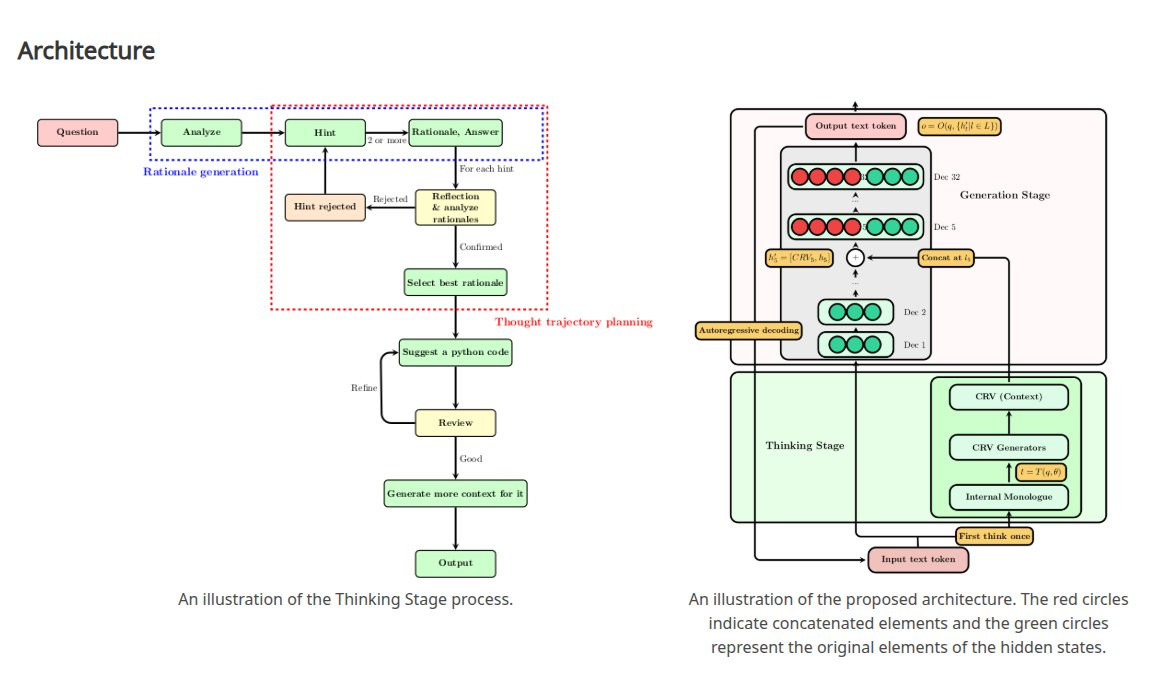
What if we could separate the reasoning process from the generation process, allowing the model to first engage in explicit contextual analysis, then inject these reasoning artifacts back into the generation pipeline at strategically chosen architectural depths?
This question motivated the development of the Neural Integration of Iterative Reasoning (NIR) framework—a method for enhancing LLM code generation through strategic integration of context representation vectors derived from explicit reasoning stages.
The discussion of Context Representation Vectors (CRVs) and their integration assumes basic understanding of neural network forward passes and attention mechanisms.
This report makes an effort to explicitly detail even fundamental aspects such as the motivation for separating reasoning from generation, or the mechanics of hidden state concatenation. The analysis progresses from basic intuitions to sophisticated architectural considerations; sequential reading is recommended for full comprehension.
Code and Reproducibility: The complete implementation is available at github.com/soran-ghaderi/nir_code_release, with detailed examples and documentation. The framework integrates with existing Hugging Face transformers (LLaMA 3.1), making reproducing straightforward for practitioners.
Highlights:
✅ It dynamically recalculates RoPE for modified hidden states and requires NO finetuning - a plug-and-play approach to enhance code generation capabilities!
✅ Using Meta’s LLaMA 3.1-8B-instruct as our testbed, we found multiple trade-offs in code characteristics depending on where integration happens.
✅ A key insight: LLMs encode simpler code features in early layers and more sophisticated patterns in later ones. -> This can be helpful for targeted manipulation
✅ The method is flexible - we can integrate arbitrary hidden states into arbitrary layers (though neighboring layers work best for model coherence).
2. Theoretical Foundation
2.1 The Reasoning-Generation Dichotomy
Traditional LLM inference conflates reasoning and generation into a single autoregressive process. Each token is generated based on the accumulated hidden states from previous tokens, but there’s no explicit mechanism for the model to “step back” and consider the broader context or alternative approaches.
NIR introduces a fundamental separation:
-
Thinking Stage: The model processes the input prompt and generates explicit reasoning about the task, producing intermediate tokens that articulate the problem understanding, potential approaches, and implementation strategies.
-
Generation Stage: The model generates the actual code, but now with access to context representation vectors derived from the thinking stage.
2.2 Context Representation Vector Formation
The core innovation lies in how we extract and process contextual information from the thinking stage. Given a thinking stage output sequence $T = [t_1, t_2, …, t_n]$, we extract hidden states $H_T = [h_1, h_2, …, h_n]$ from a specific layer $l$ of the model.
These hidden states capture different aspects of the reasoning process:
- Early tokens often contain problem decomposition
- Middle tokens typically contain approach formulation
- Later tokens frequently contain implementation planning
2.3 Integration Mechanics
The critical question becomes: where in the generation model should we inject these CRVs? Our experiments revealed that integration depth profoundly affects different aspects of code quality.
For a target layer $k$ in the generation stage, we modify the hidden states through concatenation:
\[h_{gen}^{(k)} = [h_{gen}^{(k)}; \text{CRV}]\]followed by appropriate adjustments to positional encodings and attention mechanisms to maintain architectural coherence.
3. Architectural Implementation
3.1 Model Modifications
Implementing NIR required careful modifications to several components of the LLaMA architecture:
Attention Mechanism Adaptation: The scaled dot-product attention must accommodate the increased sequence length post-concatenation while maintaining computational efficiency.
Rotary Positional Encoding Updates: Perhaps most critically, RoPE must be recalculated for the modified hidden states to preserve positional awareness.
Layer-wise Integration: Each decoder layer where integration occurs must handle the concatenation process while maintaining gradient flow and training stability.
3.2 The Integration Strategy
Our experiments focused on three integration depths:
- Layer 1 (Early): Integration near the input embeddings
- Layer 10 (Mid): Integration in the middle layers where semantic processing typically occurs
- Layer 23 (Deep): Integration near the output layers where final representations are formed
This choice was motivated by the hypothesis that different layers encode different types of information, and that strategic integration could target specific aspects of code generation quality.
4. Experimental Analysis
4.1 Evaluation Framework
We evaluated NIR using the MBPP (Mostly Basic Python Problems) dataset with LLaMA 3.1-8B-Instruct. Our evaluation encompassed multiple dimensions of code quality:
Syntactic Quality: Parse success rates and structural validity
Complexity Analysis: Cyclomatic complexity and Halstead metrics
Code Characteristics: Length, readability, and maintainability measures
4.2 Key Findings
Our results revealed a fascinating paradox: deeper integration improves some quality metrics while degrading others.
4.2.1 Response Rate and Syntactic Correctness
| Integration Depth | Response Rate | Syntactic Correctness |
|---|---|---|
| Layer 1 | 0.5799 | 0.1915 |
| Layer 10 | 0.9941 | 0.8690 |
| Layer 23 | 0.9941 | 0.9762 |
| Original | 0.9941 | 0.9762 |
Insight: Early integration (Layer 1) severely compromises the model’s ability to generate coherent responses, while deeper integration approaches original model performance.
4.2.2 Code Complexity and Structure
| Integration Depth | Cyclomatic Complexity | Lines of Code | Characters |
|---|---|---|---|
| Layer 1 | 0.4468 | 8.2234 | 217.1596 |
| Layer 10 | 2.0714 | 11.5893 | 335.9464 |
| Layer 23 | 2.5952 | 6.0952 | 198.0119 |
| Original | 2.3571 | 15.7262 | 535.0417 |
Critical Insight: Deep integration (Layer 23) produces the most concise code, while mid-layer integration (Layer 10) generates more complex but potentially more robust solutions.
4.3 The Layer-Encoding Hypothesis
These results support a key hypothesis: LLMs encode different aspects of code understanding at different architectural depths:
- Early Layers (1-5): Basic syntactic patterns and token relationships
- Middle Layers (6-15): Semantic understanding and algorithmic logic
- Deep Layers (16+): High-level abstractions and output formatting. However, the effect magnitude by deep integration, late layers, is not as verbose as the early and middle layers.
Injecting reasoning context at different depths therefore influences different aspects of the generation process.
5. Qualitative Analysis
5.1 Layer 10 Integration Example
Consider the task of checking distinct elements in a tuple. Layer 10 integration produced:
def check_distinct(tup):
return len(tup) == len(set(tup))
This solution demonstrates elegant problem understanding—the reasoning stage likely identified the mathematical equivalence between distinctness and set cardinality, and this insight was successfully integrated at the semantic processing level.
5.2 Comparative Analysis
The original model’s output for the same task:
def check_distinct(numbers):
""" Checks if all numbers in the tuple are distinct.
Args:
numbers (tuple): A tuple of integers.
Returns:
bool: True if all numbers are distinct, False otherwise.
"""
return len(numbers) == len(set(numbers))
Key Observation: The NIR-enhanced version eliminated verbose documentation while preserving functional correctness. This suggests that the reasoning stage identified the core algorithmic insight, leading to more focused code generation.
6. Limitations and Future Directions
6.1 Current Limitations
Dataset Specificity: Our evaluation focused on MBPP, which consists of relatively simple programming tasks. The framework’s performance on complex tasks remains unexplored.
Output Consistency: While NIR improves average code quality, it occasionally produces inconsistent outputs, particularly with early-layer integration.
Computational Overhead: The two-stage process increases inference time, though this could be mitigated through optimized implementation.
6.2 Future Research Directions
Multi-Layer Integration: Rather than single-point injection, simultaneous integration at multiple layers could capture different aspects of the reasoning process.
Dynamic Adaptation: Adaptive selection of integration depth based on task complexity or model confidence could optimize the trade-offs we observed.
Cross-Architecture Generalization: Testing NIR with different model architectures (GPT, Claude, etc.) would establish its broader applicability.
7. Implications for Code Generation Research
7.1 Theoretical Contributions
NIR demonstrates that explicit reasoning separation and strategic reintegration can enhance LLM capabilities without fine-tuning.
7.2 Practical Applications
The framework’s plug-and-play nature makes it immediately applicable to existing production systems. Organizations could enhance their code generation pipelines with minimal infrastructure changes.
7.3 Broader Impact
The depth-dependent quality trade-offs we discovered suggest that different integration strategies could be optimized for different use cases.
8. Conclusion
The Neural Integration of Iterative Reasoning framework represents a new approach in how we think about LLM enhancement for code generation. By separating reasoning from generation and strategically reintegrating contextual understanding, we can achieve targeted improvements in specific aspects of code quality.
Our key finding—that integration depth creates predictable trade-offs between different quality metrics—opens new avenues for research into controllable code generation. It’s possible to develop more sophisticated integration strategies that optimize for specific quality characteristics.
Final Reflection: The most intriguing aspect of this research may be what it reveals about the internal representations of large language models. The fact that strategic injection of reasoning artifacts can so dramatically alter output characteristics suggests that these models possess more sophisticated internal structure than commonly assumed. Understanding and leveraging this structure may be helpful to unlocking the next generation of AI-assisted development tools.
References
Ghaderi, S. (2024). Neural Integration of Iterative Reasoning (NIR) in LLMs for Code Generation. Master’s thesis, University of Essex. DOI: 10.13140/RG.2.2.18855.25769
Project Resources:
- Website: soran-ghaderi.github.io/nir
- Full PDF: soran-ghaderi.github.io/nir/nir.pdf
- Code Implementation: github.com/soran-ghaderi/nir_code_release
- Figures: ResearchGate Publication
This technical report synthesizes the key findings and implications of the NIR framework. For detailed methodology, implementation specifics, and complete experimental results, readers are encouraged to consult the full thesis and accompanying code repository.
Please check out the following twitter threads 🧵 :
|
|
Collaboration
I’m interested in handling OOD problems and those mentioned on my website 🌐, if you like to collaborate, please reach out to me.