Sampling from energy-based models is a core task in TorchEBM. This guide explains the different sampling algorithms available and how to use them effectively.
In energy-based models, we need to sample from the probability distribution defined by the energy function:
\[p(x) = \frac{e^{-E(x)}}{Z}\]
Since the normalizing constant Z is typically intractable, we use Markov Chain Monte Carlo (MCMC) methods to generate samples without needing to compute Z.
Langevin Dynamics is a gradient-based MCMC method that updates samples using the energy gradient plus Gaussian noise. It's one of the most commonly used samplers in energy-based models due to its simplicity and effectiveness.
importtorchfromtorchebm.coreimportBaseEnergyFunctionfromtorchebm.samplersimportLangevinDynamicsimporttorch.nnasnn# Define a custom energy functionclassMLPEnergy(BaseEnergyFunction):def__init__(self,input_dim,hidden_dim=64):super().__init__()self.network=nn.Sequential(nn.Linear(input_dim,hidden_dim),nn.SELU(),nn.Linear(hidden_dim,hidden_dim),nn.SELU(),nn.Linear(hidden_dim,1))defforward(self,x):returnself.network(x).squeeze(-1)# Create an energy functionenergy_fn=MLPEnergy(input_dim=2,hidden_dim=32)# Create a Langevin dynamics samplerdevice=torch.device("cuda"iftorch.cuda.is_available()else"cpu")langevin_sampler=LangevinDynamics(energy_function=energy_fn,step_size=0.1,noise_scale=0.01,device=device)# Generate samplesinitial_points=torch.randn(100,2,device=device)# 100 samples of dimension 2samples=langevin_sampler.sample(x=initial_points,n_steps=1000,return_trajectory=False)print(samples.shape)# Shape: [100, 2]
fromtorchebm.samplersimportHamiltonianMonteCarlofromtorchebm.coreimportDoubleWellEnergy# Create an energy functionenergy_fn=DoubleWellEnergy()# Create an HMC samplerhmc_sampler=HamiltonianMonteCarlo(energy_function=energy_fn,step_size=0.1,n_leapfrog_steps=10,device=device)# Generate samplessamples=hmc_sampler.sample(x=torch.randn(100,2,device=device),n_steps=500,return_trajectory=False)
fromtorchebm.lossesimportContrastiveDivergence# Create a loss function that uses the sampler internallyloss_fn=ContrastiveDivergence(energy_function=energy_fn,sampler=langevin_sampler,k_steps=10,persistent=True,buffer_size=1024)# During training, the loss function will use the sampler to generate negative samplesoptimizer.zero_grad()loss,negative_samples=loss_fn(data_batch)loss.backward()optimizer.step()
# Generate multiple chains in paralleln_samples=1000dim=2initial_points=torch.randn(n_samples,dim,device=device)# All chains are processed in parallel on the GPUsamples=langevin_sampler.sample(x=initial_points,n_steps=1000,return_trajectory=False)
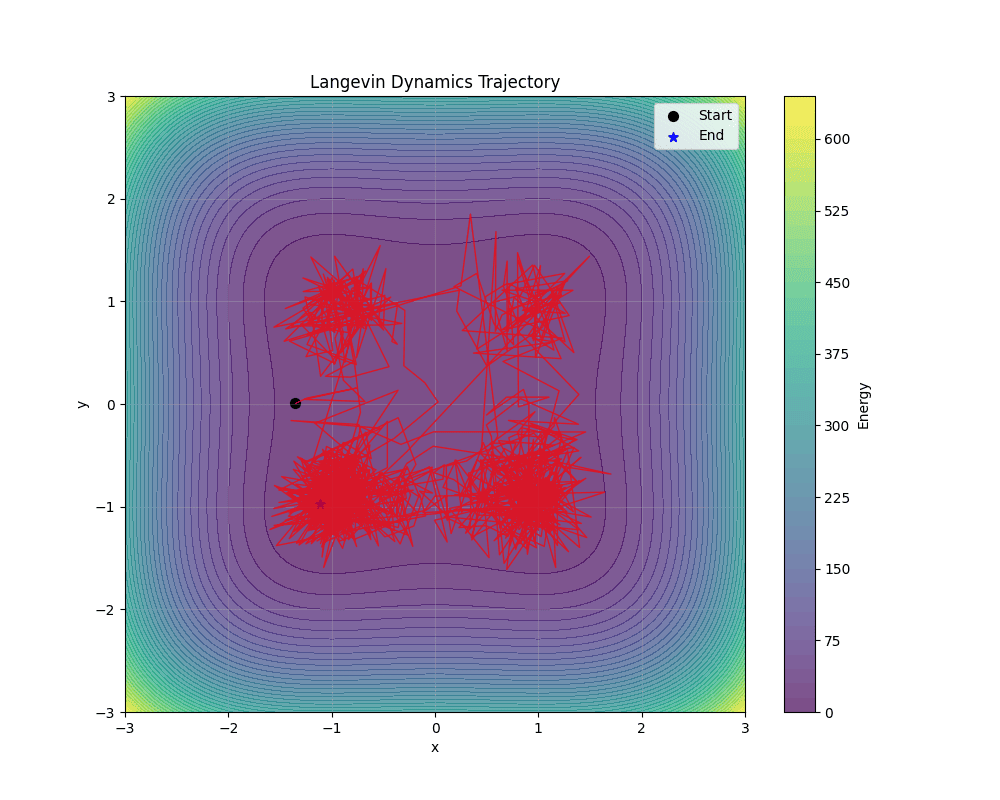
Visualizing the sampling process can help understand the behavior of your model. Here's an example showing how to visualize Langevin Dynamics trajectories:
importnumpyasnpimportmatplotlib.pyplotaspltimporttorchfromtorchebm.coreimportDoubleWellEnergy,LinearScheduler,WarmupSchedulerfromtorchebm.samplersimportLangevinDynamics# Create energy function and samplerenergy_fn=DoubleWellEnergy(barrier_height=5.0)# Define a cosine scheduler for the Langevin dynamicsscheduler_linear=LinearScheduler(initial_value=0.05,final_value=0.03,total_steps=100)scheduler=WarmupScheduler(main_scheduler=scheduler_linear,warmup_steps=10,warmup_init_factor=0.01)sampler=LangevinDynamics(energy_function=energy_fn,step_size=scheduler)# Initial pointinitial_point=torch.tensor([[-2.0,0.0]],dtype=torch.float32)# Run sampling and get trajectorytrajectory=sampler.sample(x=initial_point,dim=2,n_steps=1000,return_trajectory=True)# Background energy landscapex=np.linspace(-3,3,100)y=np.linspace(-3,3,100)X,Y=np.meshgrid(x,y)Z=np.zeros_like(X)foriinrange(X.shape[0]):forjinrange(X.shape[1]):point=torch.tensor([X[i,j],Y[i,j]],dtype=torch.float32).unsqueeze(0)Z[i,j]=energy_fn(point).item()# Visualizeplt.figure(figsize=(10,8))plt.contourf(X,Y,Z,50,cmap='viridis',alpha=0.7)plt.colorbar(label='Energy')# Extract trajectory coordinatestraj_x=trajectory[0,:,0].numpy()traj_y=trajectory[0,:,1].numpy()# Plot trajectoryplt.plot(traj_x,traj_y,'r-',linewidth=1,alpha=0.7)plt.scatter(traj_x[0],traj_y[0],c='black',s=50,marker='o',label='Start')plt.scatter(traj_x[-1],traj_y[-1],c='blue',s=50,marker='*',label='End')plt.xlabel('x')plt.ylabel('y')plt.title('Langevin Dynamics Trajectory')plt.legend()plt.grid(True,alpha=0.3)plt.savefig('langevin_trajectory.png')plt.show()
Use GPU acceleration: Batch processing of samples on GPU can significantly speed up sampling
Adjust step size: Too large → unstable sampling; too small → slow mixing
Dynamic scheduling: Use parameter schedulers to automatically adjust step size and noise during sampling
Monitor energy values: Track energy values to ensure proper mixing and convergence
5**Multiple chains**: Run multiple chains from different starting points to better explore the distribution
TorchEBM provides flexible base classes for creating your own custom sampling algorithms. All samplers inherit from the BaseSampler abstract base class which defines the core interfaces and functionalities.
fromtorchebm.coreimportBaseSampler,BaseEnergyFunctionimporttorchfromtypingimportOptional,Union,Tuple,List,DictclassMyCustomSampler(BaseSampler):def__init__(self,energy_function:BaseEnergyFunction,my_parameter:float=0.1,dtype:torch.dtype=torch.float32,device:Optional[Union[str,torch.device]]=None,):super().__init__(energy_function=energy_function,dtype=dtype,device=device)self.my_parameter=my_parameter# You can register schedulers for parameters that change during samplingself.register_scheduler("my_parameter",ConstantScheduler(my_parameter))defcustom_step(self,x:torch.Tensor)->torch.Tensor:"""Implement a single step of your sampling algorithm"""# Get current parameter value (if using schedulers)param_value=self.get_scheduled_value("my_parameter")# Compute gradient of the energy functiongradient=self.energy_function.gradient(x)# Implement your sampling logicnoise=torch.randn_like(x)new_x=x-param_value*gradient+noise*0.01returnnew_x@torch.no_grad()defsample(self,x:Optional[torch.Tensor]=None,dim:int=10,n_steps:int=100,n_samples:int=1,thin:int=1,return_trajectory:bool=False,return_diagnostics:bool=False,*args,**kwargs,)->Union[torch.Tensor,Tuple[torch.Tensor,List[dict]]]:"""Implementation of the abstract sample method"""# Reset any schedulers to their initial stateself.reset_schedulers()# Initialize samples if not providedifxisNone:x=torch.randn(n_samples,dim,dtype=self.dtype,device=self.device)else:x=x.to(self.device)# Setup trajectory storage if requestedifreturn_trajectory:trajectory=torch.empty((n_samples,n_steps,dim),dtype=self.dtype,device=self.device)# Setup diagnostics if requestedifreturn_diagnostics:diagnostics=self._setup_diagnostics(dim,n_steps,n_samples=n_samples)# Main sampling loopforiinrange(n_steps):# Step all schedulers before each MCMC stepself.step_schedulers()# Apply your custom sampling stepx=self.custom_step(x)# Record trajectory if requestedifreturn_trajectory:trajectory[:,i,:]=x# Compute and store diagnostics if requestedifreturn_diagnostics:# Your diagnostic computations herepass# Return results based on what was requestedifreturn_trajectory:ifreturn_diagnostics:returntrajectory,diagnosticsreturntrajectoryifreturn_diagnostics:returnx,diagnosticsreturnxdef_setup_diagnostics(self,dim:int,n_steps:int,n_samples:int=None)->torch.Tensor:"""Optional method to setup diagnostic storage"""ifn_samplesisnotNone:returntorch.empty((n_steps,3,n_samples,dim),device=self.device,dtype=self.dtype)else:returntorch.empty((n_steps,3,dim),device=self.device,dtype=self.dtype)
# Register a scheduler in __init__self.register_scheduler("step_size",ConstantScheduler(0.01))# Get current value during samplingcurrent_step_size=self.get_scheduled_value("step_size")# Step all schedulers in each iterationself.step_schedulers()
Device and Precision Management: The base class handles device placement and precision settings: